Sử dụng thuật toán K-Nearest Neighbors để dự đoán
(Using K- Nearest Neighbors for Prediction)
Nguyễn Văn Chức – chucnv@ud.edu.vn
Trong bài giới thiệu về thuật toán K-Nearest Neighbors (KNN) trước đây tôi đã giới thiệu cách sử dụng KNN trong bài toán phân lớp (Classification), xem KNN cho bài toán phân lớp tại đây http://bis.net.vn/forums/t/370.aspx. Bài viết này giới thiệu cách sử dụng KNN để dự đoán (Prediction).
Tư tưởng chính của thuật toán KNN vẫn không đổi, chỉ mở rộng KNN để dự đoán với các dữ liệu định lượng (quantitative data). Trong bài toán phân lớp (Classification problem), biến phụ thuộc Y là biến phân loại (categorical variable) còn trong phần dự đoán này, biến phụ thuộc Y có giá trị định lượng (Quantitative value)
Dưới đây trình bày từng bước cách sử dụng KNN trong việc dự đoán với biến phụ thuộc định lượng
1. Xác định tham số K (số láng giềng gần nhất)
2. Tính khoảng cách (Distance) giữa Query point và tất cả training samples
3. Sắp xếp khoảng cách và xác định K láng giềng gần nhất với Query point
4. Lấy giá trị của biến phụ thuộc Y tương ứng của K láng giềng gần nhất
5. Sử dụng giá trị trung bình (average) của biến phụ thuộc Y của K láng giềng gần nhất là giá trị dự đoán của Query point.
Example (KNN for prediction)
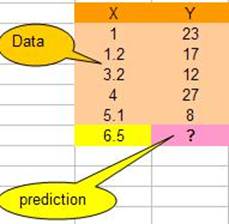
Có 5 training samples (X,Y) như sau
Vấn đề là sử dụng KNN để dự đoán giá trị của biến phụ thuộc Y của query point X=6.5
1. Xác định số láng giềng gần nhất K (Giả sử rằng K=2)
2. Tính khoảng cách giữa Query Point với tất cả training samples
Trong ví dụ này, dữ liệu về query point là 1 chiều (X) nên khoảng cách được tính đơn giản là lấy trị tuyệt đối của hiệu giữa X và các giá trị X trong training samples
Chẳn hạn, với X=5.1, khoảng cách được tính là | 6.5 – 5.1 | = 1.4, với X = 1.2 khoảng cách là | 6.5 – 1.2 | = 5.3 ,vv.
3. Săp xếp khoảng cách để xác định K láng giềng gần nhất (trong ví dụ này K=2)
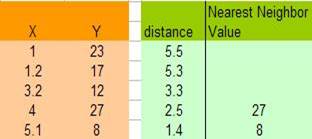
4. Lấy giá trị của biến phụ thuộc Y của K (=2) láng giềng gần nhất
Y=27 và Y=8
5. Giá trị dự đoán là trung bình của các giá trị Y của K (=2) láng giềng gần nhất.
Trong ví dụ này, giá trị dự đoán là (27+8)/2 = 17.5
Để đơn giản cho việc tính toán, ta có thể thực hiện KNN trong Excel như sau
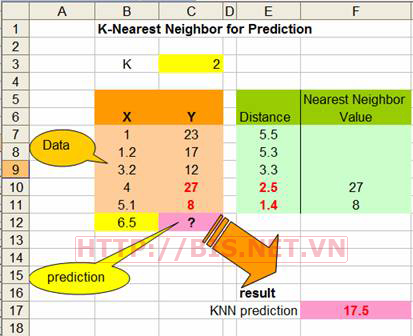
Công thức tính khoảng cách (distance) tại ô E7=ABS(B7-B$12)
Công thức xác định K láng giềng gần nhất bằng cách sử dụng hàm SMALL trong Excel như sau: F7 = IF(E7<=SMALL(E$7:E$11,$C$3),C7,"")
Công thức xác định giá trị dự đoán bằng hàm tính trung bình trong Excel như sau: F17 =AVERAGE(F7:F11)
PS. All comments please send to chucnv@ud.edu.vn. Thank you and welcome!