Xây dựng mô hình phân lớp dữ liệu với Baysesian Network
chuc 1803@gmail.com
Phân lớp dữ liệu dựa vào lý thuyết về Bayes được sử dụng rộng rãi trong khai phá dữ liệu bởi tính đơn giản, dễ hiểu (xem thêm về lý thuyết Bayes trong phân lớp dữ liệu tại đây : http://bis.net.vn/forums/t/390.aspx). Bài viết này giới thiệu về cách xây dựng mô hình phân lớp dữ liệu sử dụng Baysian Network.
Mô tả tình huống ứng dụng: Xây dựng mô hình phân lớp dữ liệu sử dụng Baysian network để dự đoán giới tính (Gender: Male|Female) dựa vào 2 thông số là độ dài của tóc (Hair Length: Short, Medium, Long) và chiều cao (Height: tính bằng cm).
Chú ý: 2 thuộc tính Gender và Hair Length có kiểu dữ liệu rời rạc (discrete) và Height có kiểu liên tục (continuous). Gender là thuộc tính phân lớp (biến phụ thuộc), Hair Length và Height là biến độc lập
1. Xây dựng mô hình (Baysian Network)
Xây dựng một Baysian Network gồm các bước sau:
1. Tạo mới một Network
2. Tạo các node cho Network
3. Liên kết các node (link)
4. Thiết lập các phân bố (distribution) của các node
5. Thực thi mô hình (Query)
6. Kiểm chứng mô hình (Evidence)
Tạo mới một Network: Click File| New để tạo một Baysian Network mới.
Tạo các node cho Network: Network| Node
Tạo node Gender: Trên Tab Network click Node, khai báo name: Gender, các giá trị (state) của node như hình sau:
Tương tự, tạo các node Hair Length và Height như sau:
Tạo liên kết (links) giữa các node
Tạo liên kết từ node Gender tới node Hair Length
Trên Tab Network, click the Link
From : Chọn Gender node.
To: Chọn Hair Length node.
Tương tự, Tạo liên kết từ node Gender tới node Height kết quả như trên:
Thiết lập các phân bố xác suất (distributions) cho các node
Giả sử ta có phân bố xác suất của giới tính P(Gender) như sau:
|
Gender = Female
|
Gender = Male
|
|
0.51
|
0.49
|
Chọn node Gender và bấm vào distribution, nhập các giá trị như sau:
Nhập phân bố xác suất của Hair Length node theo giới tính P(Hair Length | Gender), giả sử như sau:
|
Gender
|
Hair Length = Short
|
Hair Length = Medium
|
Hair Length = Long
|
|
Female
|
0.1
|
0.4
|
0.5
|
|
Male
|
0.8
|
0.15
|
0.05
|
Nhập phân bố xác suất của node Height theo giới tính, giả sử như sau:
P(Height | Gender=Female)
|
Mean
|
Variance
|
|
162.56
|
50.58
|
P(Height | Gender=Male).
|
Mean
|
Variance
|
|
176.022
|
50.58
|
Trong mục Query|Add|Explorer| Add Variable
Chọn Gender and Hair Length trong khung bên trái đưa qua khung bên phải, như sau:
Trong Tab Query Explorer, chọn Add Customer
Chọn Gender và Height , click Add, kết quả như sau:
Kiểm chứng mô hình
Giả sử muốn phân tích sự phụ thuộc của Gender và Height dựa vào Hair Length, ta thực hiện như sau :
Chọn node Hair Length trong Network Viewer.
Click nút Edit Evidence trong tab (hoặc double click vào node Hair Length), chọn giá trị cho Hair Length là Short.
Click on the Apply button, trên tab Evidence.
Tương tự, có thể đưa vào các chứng cứ (Evidence) của 1 node nào đó để phân tích mối quan hệ với các node khác trong Network
2. Sử dụng Baysian Network để phân lớp dữ liệuGiả sử có dữ liệu thu thập được gồm 100 người với dữ liệu như sau
| Gender |
Hair Length |
Height |
| Female |
Medium |
159.64532 |
| Male |
Short |
178.50209 |
| Female |
Short |
170.2725 |
| Female |
Medium |
160.31395 |
| Female |
Long |
156.32858 |
| Female |
Long |
165.43799 |
| Male |
Short |
177.59889 |
| Female |
Medium |
161.11003 |
| Male |
Short |
166.09811 |
| Female |
Long |
173.34889 |
Xem chi tiết ở file đính kèm
Mục đích: Sử dụng Bayesian network đã xây dựng ở trên để thực hiện phân lớp dữ liệu.
Data set có 100 dòng dữ liệu. Chúng ta sử dụng thuộc tính Hair Length và Height để dự đoán Gender. Trong data set có một số giá trị bị thiếu (missing), tuy nhiên đây không phải vấn đề đối với Baysian Network, model vẫn làm việc với các thuộc tính còn lại
Bước 1: Mở Baysian Network đã xây dựng như trên
Bước 2: Kết nối với dữ liệu (data set)
Trong Tab Data, chọn Data Connections, chọn Data Source chứa data set (trong ví dụ này dùng SQL Server để lưu trữ data set với database name là “DataSet”, table : TrainingData)
Chú ý: Để đơn giản, có thể sử dụng MS Excel để lưu trữ data set, khi đó connection data chọn MS Excel)
Sau khi kiểm tra kết nối data set thành công, chọn mục Batch Query, trong mục Data table chọn Data connection đã khai báo và chọn bảng dữ liệu chứa data set trong mục Data
Bấm OK, trong mục Data Map chọn Information, chọn Gender như hình sau:
Bấm OK, trong mục Batch Query, chọn các mục sau và bấm Start để xem kết quả phân lớp
· LogLikelihood
· Predict(Gender)
· PredictProbability(Gender)
· Gender
Ma trận phân lớp (Confusion matrix)
Vì trong data set có chứa giá trị đã biết của cột Gender (Actual), để xem hiệu quả dự đoán của mô hình chúng ta có thể sử dụng ma trận phân lớp.
Trong tab statistics chọn Confusion Matrix
Bấm OK, kết quả như sau:
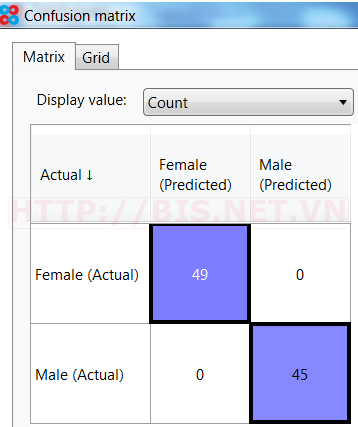
Actual: Giá trị thực tế (đã biết) của biến Gender trong data set
Predicted: Giá trị dự đoán của biến Gender được xác định bởi Model
Độ chính xác (Accuracy) của model được tính là tổng của đường chéo chia cho tổng của 4 ô trong bảng.