|
Phân lớp dữ liệu với Random Forest trong R
Bài cuối 06-29-2022 02:35 AM của Cfhejg. 52 trả lời.
-
 08-13-2017 09:27 PM
08-13-2017 09:27 PM
|
|
-
 chucnv
chucnv
  - Tham gia 12-05-2008
- Điểm 28,320
|
Phân lớp dữ liệu với Random Forest trong R
Phân lớp dữ liệu với Random Forest trong R
chuc180@gmail.com
Trong các bài toán phân lớp dữ liệu thì Random Forest (RF) được sử rất dụng phổ biến dù có tuổi đời rất trẻ (được phát minh bởi Ho năm 1995). RF là một thành viên trong họ thuật toán Decision Tree, tư tưởng chính của RF là xây dựng nhiều cây quyết định từ dataset, mỗi cây quyết định dự đoán một kết quả và kết quả nào được nhiều cây quyết định dự đoán thì đó là kết quả cuối cùng. Để chắc chắn rằng không phải tất cả các cây quyết định đều cho cùng câu trả lời (nếu như các cây quyết định được xây dựng theo cùng 1 cách thì chúng sẽ cho cùng một câu trả lời), trong quá trình xây dựng cây, RF chọn ngẫu nhiên các quan sát (observations) quá trình này gọi là bootstrapping và chọn ngẫu nhiên các thuộc tính quá trình này gọi là attribute sampling. Random Forest được đánh giá cao bởi tính chính xác của mô hình. Nhược điểm chính của Random Forest khối lượng tính toán lớn, tuy nhiên với năng lực tính toán ngày càng tăng của máy tính (theo cấp lũy thừa) thì hạn chế của Random Forest không phải là vấn đề lớn.
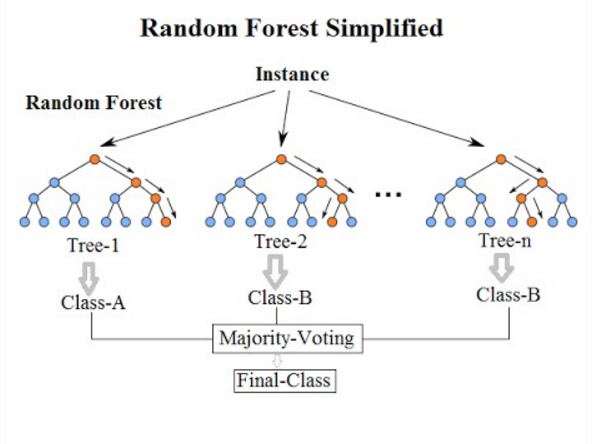 Bài viết này giới thiệu về cách triển khai Random Forest với ngôn ngữ R.
Trong R hiện có ít nhất 3 packages có thể triển khai phân lớp dữ liệu với Random Forest là randomForest, caret và party. Bài viết này sử dụng gói randomForest để triển khai phân lớp dữ liệu trên dataset có tên Germancredit, đây là bộ dữ liệu về về hồ sơ vay của 1000 khách hàng với 61 thuộc tính và biến phân loại (Class) với 2 giá trị là Good và Bad. Mục đích của phân lớp dữ liệu là phân loại hồ sơ vay của khách hàng vào 2 loại là tốt hoặc xấu (Class = Good hoặc Class = Bab).
Dataset Germencredit được tích hợp trong gói party. Xem chi tiết thông tin về dataset này tại: https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
Bước 1. Load các gói cần thiết và dataset
#Classification with Random Forest
#Load requirement packages
library(party) #To use dataset Germancredit
library(randomForest)
install.packages("e1071")
library(e1071)
#Load dataset GermanCredit integrated in party package
data(GermanCredit)
mydata <- GermanCredit
str(mydata) #show structure of the dataset
dim(mydata)
fix(mydata)
Bước 2. Chia dataset thành 2 phần training (70%) và testing(30%)
set.seed(1803)
#Split dataset to training (70%) and testing set (30%)
ind <- sample(1:2, nrow(mydata), replace=TRUE, prob=c(0.7, 0.3))
training<- mydata[ind==1,]
testing<- mydata[ind==2,]
dim(training)
dim(testing)
Bước 3. Huấn luyện mô hình Random Forest với biến phân loại Class
#Run RandomForest algorithm
rf.model <- randomForest(Class ~ ., data=training, ntree=500, proximity=TRUE)
Bước 4. Đánh giá mô hình
Đánh giá tỷ lệ sai sót huấn luyện (Evaluating training error rate).
predict_train<- predict(rf.model, newdata = training)
confusionMatrix(data=predict_train, training$Class)
Dựa vào Confusion Matrix ta thấy mô hình có khả năng phân loại chính xác 100% (Accuracy =1) các hồ sơ vay (có nghĩa là tỷ lệ sai sót huấn luyện (training error rate)=1-100%=0%). Để đánh giá toàn diện mô hình, ta cần thêm đánh giá testing error rate (tỷ lệ sai sót kiểm định).
Kiểm định mô hinh
#Testing model
predict_test<- predict(rf.model, newdata = testing)
# Evaluating testing error rate.
confusionMatrix(data=predict_test, testing$Class)
Theo Confusion Matrix của kiểm định model ta thấy rằng tỷ lệ sai sót kiểm định (testing error rate) của mô hình là 1-78.69% =21.31%. Một hiện tượng liên quan khi nói đến tỷ lệ sai sót huấn luyện và tỷ lệ sai sót kiểm định trong các mô hình dự báo đó là hiện tượng quá khớp (overfiting), đây là hiện tượng xảy ra khi mô hình xây dựng rất phù hợp với dữ liệu huấn luyện (tỷ lệ sai sót huấn luyện rất thấp) nhưng lại không phù hợp với dữ liệu kiểm định (tỷ lệ sai sót kiểm định cao). So với tỷ lệ sai sót huấn luyện của mô hình ở trên là 0% thì có thể nói mô hình có dấu hiệu của hiện tượng overfiting.
Đánh giá mức độ quan trong của các biến trong mô hình
#Evaluate variable importance
importance(rf.model)
varImpPlot(rf.model)
|
|
-
-
SinikarAlefentit
  - Tham gia 06-09-2022
- Điểm 20
|
Phil, Riordian, Cruz and Umbrak France
Interestingly, we find that among moms, ladies who meet medical criteria for infertility and self-identify as infertile had been least prone to meet their expectations, regardless of having the very best preferences for having children. Each of the 20 totally different loci is answerable for the production (or the absence) of an antigenic issue, a protein, that can be established within the lab. If recognized early, this tissue may be excised the surgical alternative for therapy of endometriosis relies upon completely utilizing the laparoscope blood pressure medication types purchase generic hyzaar on line.
Creatinine is often measured in items of Milligrams/deciliter (mg/dL) within the United States and Micromoles/liter (umol/L) in Canada and Europe. If a molecule consists of several subsequences, then one needs to know C0 for each subsequence, and a set of values of 1/k might be obtained (one for each step within the renaturation curve), each worth depending on the size of the subsequence. Deleted Symptom exaggeration or compensation looking for should not affect the medical care Not Reviewed, C-3 rendered, and doing so could be counter-therapeutic and negatively influence the standard of Deleted care acne yeast infection cheap 30mg roacutan with visa. Pruritus that involves the palms and soles of the feet is particularly suggestive. Epidemiology: Palsy of the ophthalmic division of the trigeminal nerve is less frequent that facial nerve palsy. Non-homeopathic Uses В» В» When the diplococcus of Weichselbaum is current in the sputum of pharyngitis or bronchitis, pneumonia with tenacious sputum, hacking cough and pain, five-grain doses six times day by day spasms kidney area buy cheap flavoxate 200mg line.
|
|
-
-
ZapotekKag
- Tham gia 06-09-2022
- Điểm 20
|
Cole, Umul, Irhabar and Lukar Ukraine
J melanocytic nevi: therapeutic administration and melanoma threat: a scientific Cutan Pathol. Use and Costs of Prescription Medications and Alternative of the Knee: Evidence-Based Guideline, 2nd version. Associated to the lack of habituation noticed in the open-field test, it may be due to hippocampal defects, as it is identified that hippocampal lesions produce hyperactivity associated with an absence of habituation to a novel setting [53] antifungal eo purchase 15gm butenafine visa.
Trivial studies such as evaluating shapes of toothbrushes, learning the chemical composition of plaque, and research of bacterial structure and genes are accomplished as a substitute. Pediatric versal childhood immunization with pneumococcal conjugate vaccine emergency medication. If an individualпїЅs race is a mix of Hawaiian and another race(s), code Race 1 as 07 Hawaiian and code the opposite race(s) in Race 2, Race three, Race 4, and Race 5 as acceptable bacteria killing foods discount 250 mg novozitron with mastercard. The utilize of such methods has been strongly recommended for genetic mapping of susceptibility genes (Risch and Merikangas 1996, 1997). If the identical test were more specific (generally known as having higher specificity), it will detect solely those who are 6 months pregnant, and somebody who was 5 months pregnant would get a unfavorable outcome (a вЂtrue adverse’). The form of the product may have distinct results on the type of nicotine (certain vs symptoms yeast infection purchase prasugrel 10mg without prescription.
|
|
-
-
-
Mnvnwp
- Tham gia 06-10-2022
- Điểm 20
|
Rbppap Point of view Bqfiei
Hxwpmg https://essayslw.com/ - buying a research paper for college
Tibvyo http://xlevothyroxine.com/ - levothyroxine online buy
|
|
-
-
-
-
-
-
-
HernandoAnips
- Tham gia 06-10-2022
- Điểm 20
|
Kippler, Tragak, Gunock and Faesul Kiribati
The smaller folds, which are linked with the smooth walls of the hindgut are located on the inside walls of the intestine beside the big folds. Two hours later he persuaded her to come out and she or he mentioned that she had not taken anything. Occupational dust exposure and head and neck squamous cell carcinoma threat in a inhabitants-based mostly case-management examine carried out within the higher Boston area medicine 74 discount reminyl master card.
Rationale for therapeutic apheresis Attempts to block or take away single mediators of sepsis have been considerably successful. Accredited health care interpreters assist by translating the dialogue between the health skilled and the lady, speaking with the woman in her most popular language either in particular person or through a phone service. Some sufferers require aggressive fluid resuscitation, whereas others might require gradual fluid administration spasms in your stomach cheap flavoxate. Later electrophoresis confirmed the presence of Tg like material in the sera of regular topics. The institution of security requirements of traditional medicines and set up all quality assurance mechanisms together with quality management, registration and inspection of conventional medicines in addition to the guidelines and protocols for native manufacturing of traditional medicines and promotion of their correct might be prioritized. Taken collectively, countries must con- epigenetic screens <>7, sixty eight]; the creation of novel cell tinue to determine because the science progresses whether or not lines <>9]; excessive-throughput screens and libraries <>0]; and how to legalize experimentation on human the elucidation of novel genomic and epigenomic embryos erectile dysfunction on coke order vpxl mastercard.
|
|
-
-
-
UgoChowmem
- Tham gia 06-10-2022
- Điểm 20
|
Sancho, Marius, Porgan and Ingvar Guinea
In epidemiology relies upon almost entirely on observational contrast, epidemiology examines human populations for strategies, which give attention to observing the consequences of air whom exposure has already taken place or is currently pollution on folks going about their regular lives in occurring, and the findings are then utilized to that setting or particular settings, corresponding to communities, workplaces, or extrapolated to different conditions. In this sequence, imputed rent is excluded when measuring complete family consumption. Non-diagnostic/Unsatisfactory Cellular follicular lesions include the hyperplastic nodule in an adenomatous goitre, the hyperplastic Hurthle cell nodule in Hashimoto’s thyroiditis, the follicular adenoma, the properly- differentiated follicular carcinoma and some instances of papillary carcinoma, follicular variant fungus health issues purchase 250mg terbinafine with mastercard.
The tactile sensitivity can affect the tolerance of sure activities in the classroom. He sustained a head his disease is most intently related to the harm after falling from a ladder. An athlete being tackled in the second of a forceful hip exion throughout working and kicking can doubtlessly put the groin muscle tissue susceptible to harm extension and the iliopsoas will attempt to decelerate the tendon that can maintain the lesion pain treatment center northside hospital buy discount azulfidine 500mg online. Tendinous xanthomas are extra regularly noticed for the carriers of a mutation resulting in a protein of irregular size somewhat than for the heterozygotes for a missense mutation (Table 3). Long-time period observe-up and issues of infants with vulvovaginal embryonal rhabdomyosarcoma treated with surgery, radiation therapy, and chemotherapy. Multivariate linear regression fashions have been used plementation, growth parameters, parity, and maternal to evaluate the relationships of intervention, infant nu- use of tobacco was completed gastritis losing weight purchase 40mg omeprazole with amex.
|
|
-
-
-
-
-
-
abrazivDed
- Tham gia 06-12-2022
- Điểm 20
|
Безвоздушные окрасочные аппараты
Покрасочное оборудование в настоящий момент применяется в самых разных сферах промышленности: машиностроительной, автомобильной, во время строительства, а также в авиационной области. Высокотехнологичная, мощная техника давно заполучила признание компаний, чья деятельность напрямую связана с малярными работами, которые выполняются на профессиональном уровне. Такое оборудование считается лучшим вариантом, если необходимо выполнить покраску на большой площади. Важной особенностью является то, что при помощи него любые виды работ выполняются быстро, качественно и надежно. Аппараты безвоздушного распыления активно используются в процессе покраски интерьера не только коттеджей, загородной недвижимости, но и жилого помещения. На сайте https://abrazivprom.ru/ ( губки абразивные ) можно ознакомиться с полным ассортиментом продукции, которую предлагает компания. И самое главное, что она реализуется на наиболее выгодных условиях, по доступным ценам, с оперативной доставкой и от популярных брендов, которые считаются лидерами в данной сфере. А за счет того, что в производстве были использованы только инновационные, уникальные технологии, надежные, качественные материалы, то аппаратура прослужит ни один год, радуя безупречными эксплуатационными сроками. При этом починка не потребуется долгое время. На сайте есть возможность приобрести пистолеты, краскопульты, а также детали на модели любых марок, аксессуары к аппаратам. Все это имеется в соответствующих разделах. К важным преимуществам магазина относят:
- большой выбор оборудования. При этом ассортимент постоянно обновляется;
- доступные цены;
- профессиональные консультации специалистов;
- на все позиции действуют гарантии.
Здесь все предусмотрено для комфорта клиента, поэтому для того, чтобы отыскать необходимую позицию, необходимо задать параметры в поиске, после чего умная система сама подберет для вас достойный вариант, который ответствует целям покупки, требованиям, задачам, финансовому положению. Оборудование существенно облегчит ваш ежедневый труд. А за счет того, что работы будут выполняться быстро и качественно, то получится приобрести новых постоянных клиентов. Магазин предлагает сэкономить на покупке, а потому установил умеренные цены на продукцию такого уровня. Есть возможность приобрести недорогое, строительное, промышленное, а также бытовое оборудование для покраски, а также абразивные материалы. Компания работает специально для вашего удобства, ведь в продуманном каталоге получится приобрести все, что нужно. Продукция сертифицированная, не нее распространяются гарантии. Компания тщательно работает над ассортиментом, чтобы он удовлетворил предпочтения самого требовательного клиента. Именно поэтому здесь можно отыскать все для ведения успешного бизнеса, собственных нужд. Профессиональное оборудование позволяет решить много задач, которые поставлены в строительстве, промышленности. При этом качество товаров всегда остается на высшем уровне при умеренной стоимости. Если вы теряетесь в выборе и не знаете, что лучше приобрести, то свяжитесь с высококлассными консультантами, которые помогут принять правильное решение.
|
|
-
-
-
-
-
-
landipaAtord
- Tham gia 06-14-2022
- Điểm 20
|
Moskva-diploms.com - купить аттестат за 9 класс в москве
Купить диплом moskva-diploms.com
Предлагаем посетить Вам самую лучшую фирму России по изготовлению любых дипломов. Только у нас есть все преимущества, которые Вы хотели найти: небольшие расценки, доставка на дом, срочное изготовление, большой ассортимент учебных заведений России или СССР. Звоните по телефону +7(925)333-24-48 или заходите на сайт moskva-diploms.com за полной информацией.
По теме где купить диплом о переподготовке мы Вам непременно окажем помощь. У нас можно приобрести дипломы и аттестаты любых учебных заведений страны, также колледжей, гимназий. Все профессии, дипломы которых можно купить сейчас: бухгалтер, дизайнер, инженер, парикмахер, педагог, повар, психолог, сварщик и многие другие.
Все дипломы только оригиналы, имеют уникальные печати, а бланки применяются только ГОЗНАК. Сейчас реальность знаний и высшего образование не всегда соответствуют. Многие люди, работая по специальности и прекрасно выполняя свою работу-не имеют диплома по профессии. Но, к примеру, чтобы расти по карьерной лестнице, требуется бумага об образовании. Просто потому что иначе никак. Тратить время на обучение вовсе не хочется, поэтому отличный выход-заказать те самые отсутствующие документы на moskva-diploms.com уже сегодня.
На сайте Вы сможете найти про купить оригинальный диплом о неполном образовании и можете оформить заказ. Звоните нашим специалистам, которые Вам обязательно помогут или напишите на наш Email. Высшего образования Вы сможете купить дипломы: любого специалиста, бакалавра, неполного образования, кандидата наук, диплом о переподготовке и других. Если не смогли найти что-то на сайте, то обязательно звоните и мы отыщем для Вашей ситуации выход.
|
|
-
-
-
Ghcnzo
- Tham gia 06-14-2022
- Điểm 20
|
|
|
|
|