Vấn đề trích chọn thuộc tính trong Khai phá dữ liệu (Feature Selection in Data Mining)
Nguyễn Văn Chức – chuc1803@gmail.com
1. Sơ lược về trích chọn thuộc tính
Trích chọn thuộc tính (Feature Selection, Feature Extraction) là nhiệm vụ rất quan trọng giai đoạn tiền xử lý dữ liệu khi triển khai các mô hình khai phá dữ liệu. Một vấn đề gặp phải là các dataset dùng để xây dựng các Data mining Models thường chứa nhiều thông tin không cần thiết (thậm chí gây nhiễu) cho việc xây dựng mô hình. Chẳn hạn, một dataset gồm hàng trăm thuộc tính dùng để mô tả về khách hàng của một doanh nghiệp được thu thập, tuy nhiên khi xây dựng một Data mining model nào đó chỉ cần khoảng 50 thuộc tính từ hàng trăm thuộc tính đó. Nếu ta sử dụng tất cả các thuộc tính (hàng trăm) của khách hàng để xây dựng mô hình thì ta cần nhiều CPU, nhiều bộ nhớ trong quá trình Training model, thậm chí các thuộc tính không cần thiết đó làm giảm độ chính xác của mô hình và gây khó khăn trong việc phát hiện tri thức.
Các phương pháp trích chọn thuộc tính thường tính trọng số (score) của các thuộc tính và sau đó chỉ chọn các thuộc tính có trọng số tốt nhất để sử dụng cho mô hình. Các phương pháp này cho phép bạn hiệu chỉnh ngưỡng (threshold) để lấy ra các thuộc tính có Score trên ngưỡng cho phép. Quá trình trích chọn thuộc tính luôn được thực hiện trước quá trình Training Model.
Một số phương pháp chọn thuộc tính (Feature Selection Methods)
Có rất nhiều phương pháp để lựa chọn thuộc tính tùy thuộc vào cấu trúc của dữ liệu dùng cho mô hình và thuật toán được dùng để xây dựng mô hình. Sau đây là một số phương pháp phổ biến dùng trong trích chọn thuộc tính:
interestingness score: Được sử dụng để xếp hạng (rank) các thuộc tính đối với các thuộc tính có kiểu dữ liệu liên tục (continuous). Một thuộc tính được xem là Interesting nếu nó mang một vài thông tin hữu ích (thế nào là thông tin hữu ích tùy thuộc vào vấn đề đang phân tích của bạn). Để đo lường mức độ interestingness, người ta thường dựa vào entropy (một thuộc tính với phân bố ngẫu nhiên có entropy cao hơn và có information gain (độ lợi thông tin) thấp hơn) vì vậy các thuộc tính đó gọi là less interesting).
Entropy của một thuộc tính nào đó sẽ được so sánh với entropy của tất cả các thuộc tính còn lại theo công thức sau:
Interestingness(Attribute) = - (m - Entropy(Attribute)) * (m - Entropy(Attribute))
Trong đó m gọi là entropy trung tâm (Central entropy- có nghĩa là entropy của toàn bộ tập thuộc tính)
Shannon's Entropy: Được sử dụng đối với các dữ liệu kiểu rời rạc (discretized data).
Shannon's entropy đo lường độ bất định (uncertainty) của biến ngẫu nhiên đối với một kết quả cụ thể (particular outcome). Ví dụ, entropy của việc tung một đồng xu có thể biểu diễn bằng một hàm của xác suất của khả năng xuất hiện mặt sấp hay ngửa
Shannon's entropy được tính theo công thức sau
H(X) = -∑ P(xi) log(P(xi))
Ngoài interestingness score và Shannon's entropy, một số phương pháp khác cũng thường được sử dụng trong lựa chọn thuộc tính như Bayesian with K2 Prior, Bayesian Dirichlet Equivalent with Uniform Prior
Dưới đây là các phương pháp trích chọn thuộc tính được triển khai trong Analysis Services của Microsoft
2. Giới thiệu trích chọn thuộc tính với phần mềm WeKa
Phần này giới thiệu việc trích chọn thuộc tính thông qua phần mềm chuyên khai phá dữ liệu Weka. Dataset dùng để minh họa là file định dạng chuẩn của weka mushroom-train.arff gồm 2000 instances và 23 thuộc tính (download dataset tại đây).
Khởi động Weka > Chọn Explorer > Chọn Open file > Chọn Dataset “mushroom-train.arff” kết quả như sau:
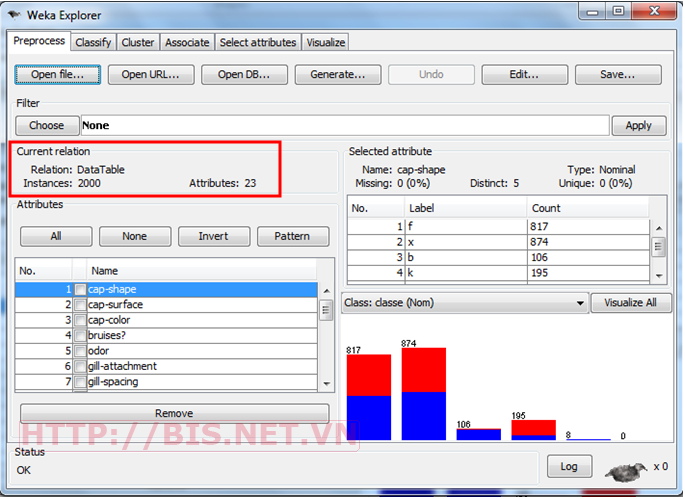
Chọn Tab “Select attributes”. Trong mục Attribute Evaluator chọn WrapperSubsetEval. Trong mục classifier chọn NaiveBayes
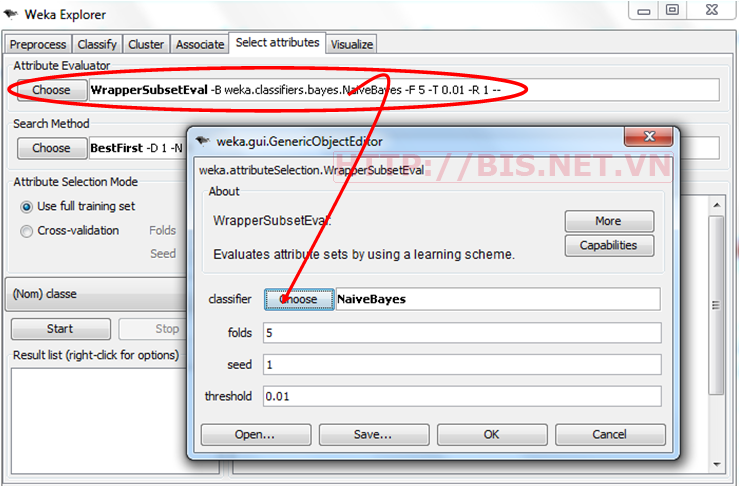
Trong mục Search Method chọn “GreedyStepwise” như sau:
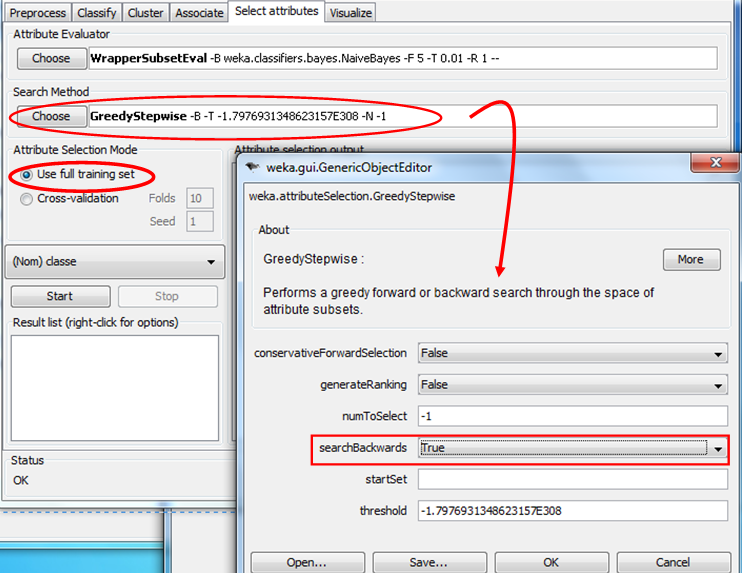
Bấm Start để thực hiện, kết quả như sau:
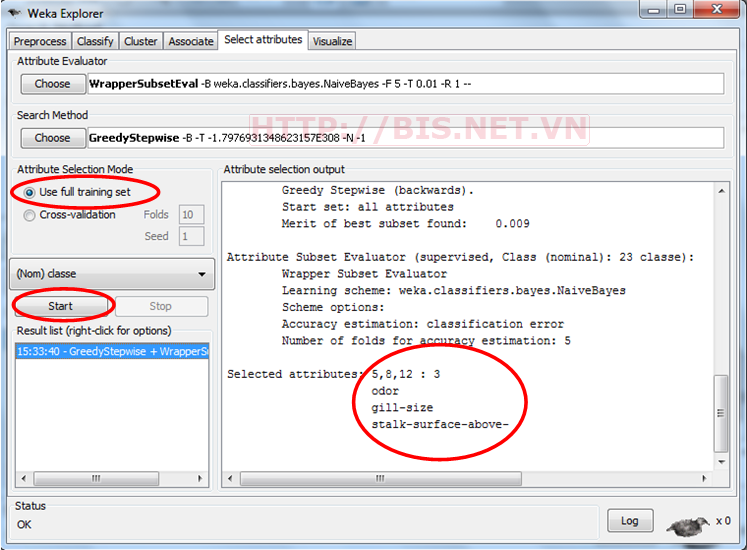
3 thuộc tính được chọn đó là Odor, gill-size và stalk-surface-above
Đánh trọng số các thuộc tính sử dụng Cross Validation
Sử dụng phương pháp trích chọn thuộc tính như trên ta thu được tập các thuộc tính tối ưu thay cho tập thuộc tính ban đầu. Nhưng ta biết rằng, kết quả của việc chọn thuộc tính phụ thuộc rất lớn vào training dataset. Nếu sử dụng một dataset khác có thể thu được tập thuộc tính khác và có khi các kết quả rất khác nhau.
Để khắc phục hạn chế này, Weka cho phép sử dụng kỹ thuật Cross validation để đánh trọng số các thuộc tính tùy thuộc vào số lần xuất hiện của chúng trong toàn bộ quá trình Training Model.
Để thực hiện đánh trọng số các thuộc tính sử dụng Cross validation, ta chọn ATTRIBUTE SELECTION MODE = CROSS-VALIDATION (FOLDS = 10) và bấm nút Start để thực hiện
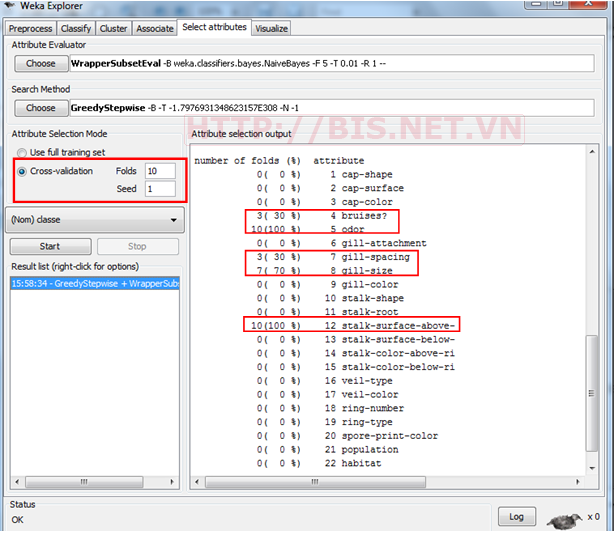
Sử dụng Cross- validation, ta có tập thuộc tính tối ưu là bruises (xuất hiện 3 lần), odor ( xuất hiện 10 lần), gill-spacing ( xuất hiện 3 lần), gill-size (xuất hiện 7 lần) và stalk-surface-above ( xuất hiện 10 lần).
Xếp hạng các thuộc tính (Ranking attributes)
Weka cho phép xếp hạng các thuộc tính, theo phương pháp tìm kiếm backward (backward search) thì những thuộc tính ít quan trọng sẽ được loại bỏ ra khỏi tập thuộc tính trước và thuộc tính quan trọng nhất sẽ được loại bỏ sau cùng. Weka xếp hạng cho mỗi thuộc tính theo cách này.
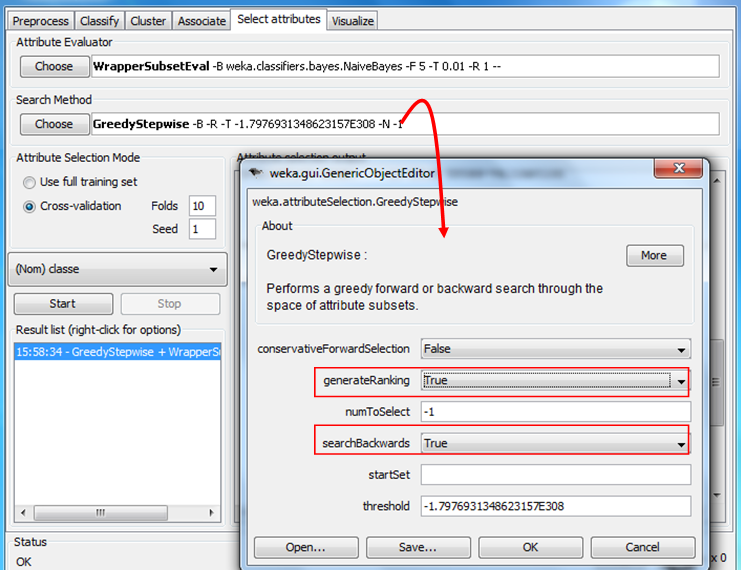
Để thực hiện xếp hạng các thuộc tính, trong mục SEARCH METHOD, đặt GENERATE RANKING = TRUE. (Xem hình sau)
Kết quả Ranking như sau:
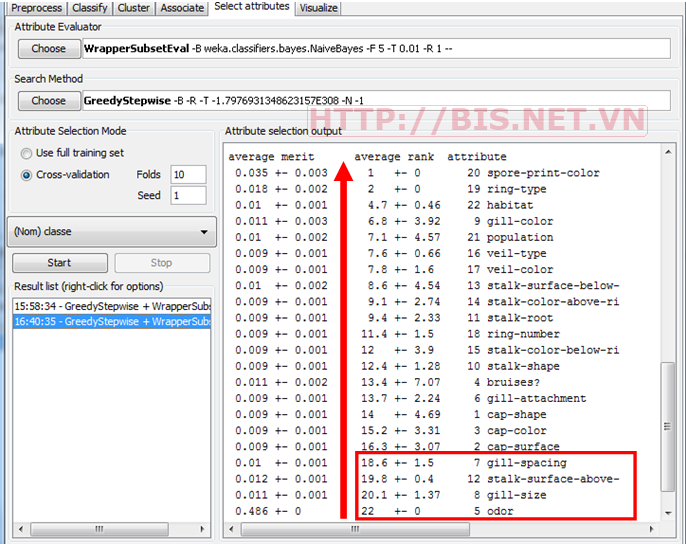
Average rank: Vì chúng ta sử dụng phương pháp tìm kiếm backward cho nên chúng ta phải đọc kết quả từ dưới lên. Trong cột Average rank, từ dưới lên (from bottom to top) mức độ quan trọng của các thuộc tính giảm dần. Thuộc tính odor có thứ hạng cao nhất là 22 (quan trọng nhất) sau đó là gill-size, stalk- sureface-above-,…
Ta thấy rằng qua các phương pháp chọn thuộc tính trên, kết quả khá ổn định. Tập thuộc tính tối ưu luôn chứa các thuộc tính là odor, gill-size , stalk-surface-above , gill-spacing, bruises
Thông thường, để tìm được tập thuộc tính tối ưu thay thế cho tập thuộc tính ban đầu của dataset, người ta thường kết hợp nhiều phương pháp trích chọn thuộc tính, từ đó so sánh và chọn ra tập thuộc tính tối ưu sử dụng để xây dựng các mô hình khai phá dữ liệu.