Một ít kiến thức Thống kê cho khai phá dữ liệu
Nguyễn Văn Chức – chuc1803@gmail.com
Ta biết rằng 4 lĩnh vực liên quan của khai phá dữ liệu gồm thống kê (statistics), Máy học (Machine Learning), Cơ sở dữ liệu (Database) và trực quan hóa dữ liệu (Visualization). Trong 4 lĩnh vực này thì thống kê đóng vài trò rất quan trọng trong quá trình khai phá dữ liệu nhất là trong kiểm định kết quả của mô hình và trong đánh giá tri thức phát hiện được.
Bài viết này giới thiệu sơ lược về các khái niệm cơ bản của thống kê dùng trong mô tả dữ liệu như các tham số đo lường xu hướng tập trung của dữ liệu (mean, Median, mode) và đo lường sự biến thiên của dữ liệu (Rang, Variance và Standard Deviation, Standard Error).
Để dễ hình dung, ta bắt đầu với ví dụ đơn giản sau:
Giả sử rằng bạn chạy 100 m trong sáu lần, mỗi lần chạy bạn dùng đồng hồ đo lại thời gian chạy (tính bằng giây) và kết quả 6 lần chạy của bạn gồm sáu giá trị (còn gọi là quan sát) như sau:
x={25.1, 21.2, 17.9, 23.0, 24.6, 19.5}
Dữ liệu này cho bạn biết những thông tin gì? Sau đây là một số thống kê đơn giản của dữ liệu về thời gian chạy 100m của bạn:
- Thời gian chạy trung bình (mean) là 21.9 giây
- Giá trị giữa (còn gọi là trung vị - median) là 22.1 giây
- Thời gian chạy nhiều nhất (maximum) là 25.1 giây và thời gian chạy ít nhất (minimum) là 17.9giây. Nếu so sánh với kỷ lục thế giới về 100m là 9.78 giây thì bạn biết rằng mình chạy để tập thể dục cho khỏe chứ không phải là vận động viên điền kinh chuyên nghiệp!
- Phương sai (variance) là 8.2 giây bình phương và độ lệch chuẩn (standard Deviation) là 2.9 giây
Đo lường số đo xu hướng tập trung (Central Tendency)
Để đo lường xu hướng tập trung của dữ liệu người ta thường dùng 3 tham số đó là số trung bình (trung bình số học - Arithmetic mean hay average), số trung vị (median) và số mode.
Mean (số trung bình): Trung bình số học được tính đơn giản bằng tổng của tất cả các giá trị của dữ liệu trong mẫu chia cho kích thước mẫu.

Với dữ liệu về chạy 100m trên ta có

Median (trung vị):
Trong lý thuyết xác suất và thống kê, số trung vị (Median) là giá trị giữa trong một phân bố chia phân bố thành 2 nhóm mà trong đó số các số trong mỗi nhóm bằng nhau. Nói cách khác, nếu m là trung vị của một phân bố nào đó thì 1/2 cá thể trong phân bố đó có giá trị nhỏ hơn hay bằng m và một nửa còn lại có giá trị bằng hoặc lớn hơn m.
Median được tính như sau: Sắp xếp dữ liệu và lấy giá trị ở giữa. Nếu số giá trị là một số chẳn thì median là trung bình của 2 giá trị ở giữa. Với số liệu trên ta có median=22.1
Công thức chung để tính median là:
Ký hiệu:
 : Số nguyên lớn nhất nhỏ hơn p ( floor function).
: Số nguyên lớn nhất nhỏ hơn p ( floor function).
 : Số nguyên nhỏ nhất lớn hơn p (ceiling function)
: Số nguyên nhỏ nhất lớn hơn p (ceiling function)
x(p): Trả về giá trị tại vị trí p trong mẫu x sau khi đã sắp xếp x tăng dần.
Trong ví dụ trên ta có n=6,
Mode (Yếu vị)
Mode là số có tần suất xuất hiện nhiều nhất trong mẫu. Nếu trong mẫu không có số nào xuất hiện lặp lại thì không có mode.
Với mẫu dữ liệu trên thì không có mode.
So sánh giữa Mean, Median và Mode
Trong 3 tham số Mean, Mode và Median thì Median có khả năng đo lường xu hướng tập trung của dữ liệu mạnh nhất.
Trở lại ví dụ chạy 100 m trên, giả sử sau khi chạy hết 6 lần, bạn chạy tiếp lần thứ 7. Lần này đột nhiên chân bạn bị đau và bạn đi bộ thay vì chạy và kết quả thời gian của lần này là 79.9 giây. Bạn cố gắng thử thêm lần nữa và kết quả vẫn 79.9 giây. Bây giờ ta có Sample về 8 lần chạy như sau:
x={25.1, 21.2, 17.9, 23.0, 24.6, 19.5, 79.9, 79.9}
Các giá trị Mean, Median và Mode so sánh giữa 2 Sample như sau:
|
Central tendency
|
6 measurements
|
8 measurements
|
|
Mean
|
21.9 giây
|
36.4 giây
|
|
Median
|
22.1 giây
|
23.8 giây
|
|
Mode
|
Not available
|
79.9 giây
|
Nếu bạn quan sát cẩn thận, đối với 6 lần chạy đầu tiên thì thời gian chính gian chạy còn 2 lần sau có sự khác biệt rất lớn so với 6 lần chạy ban đầu (2 giá trị này được xem là bất thường của dữ liệu – outlier) thực chất nó không phải thời gian chạy mà là thời gian đi bộ. Nếu bạn không bị đau thì thời gian chạy dao động quanh Median. Theo bảng trên ta thấy rằng 2 Outliers không ảnh hưởng nhiều đến Median (từ 22.1 lên 23.8) nhưng ảnh hưởng rất lớn đến Mean (từ 21.9 lên 36.4) và Mode. Mặc dù Median có khả năng đo lường xu hướng tập trung của dữ liệu mạnh hơn Mean vì Median không bị ảnh hưởng bởi các Outliers nhưng nhiều người vẫn thích sử dụng Mean để đo lường xu hướng tập trung của dữ liệu vì dễ tính hơn không cần phải sắp xếp dữ liệu như Median.
Mode rất hữu ích đối với dữ liệu có kiểu dữ liệu phân loại (nominal). Đối với các dữ liệu có kiểu phân loại ta không thể dùng Mean hay Median vì nó không có ý nghĩa gì mà phải dùng Mode. Ví dụ nếu dữ liệu mô tả giới tính là nominal và 1 là nam, 0 là nữ thì Mean hay Median là 0.5 không có ý nghĩa gì. Trong khi đó Mode cho biết tần suất nam hay nữ xuất hiện nhiều nhất.
Quartiles (tứ phân vị)
Tứ phân vị là đại lượng mô tả sự phân bố và sự phân tán của tập dữ liệu. Tứ phân vị có 3 giá trị, đó là tứ phân vị thứ nhất (Q1), thứ nhì (Q2), và thứ ba (Q3). Ba giá trị này chia một tập hợp dữ liệu (đã sắp xếp dữ liệu theo trật từ từ bé đến lớn) thành 4 phần có số lượng quan sát đều nhau.
Tứ phân vị được xác định như sau:
· Sắp xếp các số theo thứ tự tăng dần
· Cắt dãy số thành 4 phàn bằng nhau
· Tứ phân vị là các giá trị tại vị trí cắt
Độ trải giữa (Interquartile Range - IQR)
Interquartile Range được xác định như sau:
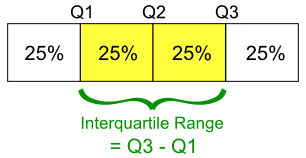
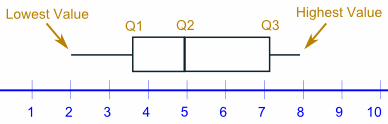
Box Plot (Biểu đồ hộp)
Box Plot giúp bạn biểu diễn các đại lượng quan trọng của dãy số như min, max, Quartile, Interquartile Range một cách trực quan, dễ hiểu. Một Box plot có dạng như sau:
Đo lường sự biến thiên của dữ liệu (Variation of Data)
Để biết xu hướng tập trung của dữ liệu ta dùng các tham số như Mean, Median, Mode. Tuy nhiên, một câu hỏi quan trọng nữa cần phải trả lời khi xem xét một chất lượng của mẫu là “làm sao đo lường sự biến thiên (hay sự phân tán) của dữ liệu trong mẫu?” Vì có thể 2 mẫu có cùng trung bình nhưng sự biến thiên của dữ liệu là khác nhau.
Để đo lường sự biến thiên (thường so với giá trị trung bình) của dữ liệu người ta thường dùng các tham số Range (khoảng biến thiên), Interquartile Range (IQR – Khoảng tứ phân vị), Standard Deviation (độ lệch chuẩn), Variance (phương sai), Standard Error (sai số chuẩn)
Range (Khoảng biến thiên): Được tính bằng cách lấy giá trị lớn nhất – giá trị nhỏ nhất
Range = Max – Min
Trong sample gồm 6 quan sát về thời gian chạy 100 m trong ví dụ trên ta có
Range = 25.1- 17.9 = 7.2 giây
Deviation (độ lệch)
Cả 2 tham số Range và IQR không quan tâm đến giá trị trung tâm (thường sử dụng giá trị trung bình). Khi muốn đo lường sự phân tán của dữ liệu so với giá trị trung tâm, ta đo lường độ lệch của mỗi quan sát (cá thể) so với giá trị trung tâm. Giả sử ta sử dụng giá trị trung bình làm giá trị trung tâm, khi đó ta có tổng độ lệch của tất cả quan sát với giá trị trung bình là:
Vì tổng độ lệch này bằng 0 nên ta không thể dùng độ lệch này để mô tả sự phân tán của dữ liệu.
(Đặc trưng của số trung bình toán học (mean) là san bằng mọi bù trừ. Vì vậy khi tính tổng tất cả các độ lệch thì kết quả luôn bằng 0)
Để khắc phục vấn đề này, ta có thể sử dụng tổng các giá trị tuyệt đối các độ lệch

Để loại bỏ ảnh hưởng của kích thước mẫu (vì mỗi mẫu có kích thước khác nhau) ta chia tổng này cho kích thước mẫu, ta có:

Tuy nhiên vấn đề của giá trị tuyệt đối là tính không liên tục (discontinuity) tại gốc tọa độ (trong trường hợp này là mean) vì vậy các nhà thống kê đã tìm ra công thức tốt hơn để mô tả sự biến thiên của dữ liệu đó là phương sai (Variance) và độ lệch chuẩn (Standard Deviation).
Variance (Phương sai) và độ lệch chuẩn (Standard Deviation)
Để tránh tổng các độ lệch bằng 0 và loại bỏ ảnh hưởng của kích thước mẫu người ta tính tổng bình phương các độ lệch và chia cho kích thước mẫu trừ 1 (hiệu chỉnh). Ta có kết quả là “trung bình tổng bình phương các độ lệch” và gọi là phương sai mẫu (Sample Variance)

Phương sai là tham số rất tốt để đo lường sự biến thiên (hay phân tán) của dữ liệu trong mẫu vì nó đã quan tâm đến độ lệch của mỗi quan sát so với số trung bình, loại bỏ ảnh hưởng của kích thước mẫu và là smooth Function. Tuy nhiên, điểm yếu của phương sai là không cùng đơn vị tính với Mean. Đơn vị tính của phương sai là bình phương của đơn vị tính của trung bình. Chẳn hạn, đơn vị tính của thời gian chạy trung bình là giây trong khí đó đơn vị tính của phương sai là giây bình phương. Để giải quyết vấn đề này, người ta lấy căn bậc 2 của phương sai và kết quả này gọi là độ lệch chuẩn (Standard Deviation)

Một vấn đề nữa cần quan tâm là mỗi lần lấy mẫu ta có 1 số trung bình (mean) và từ đó ta tính được phương sai của mẫu. Phương sai của mẫu cho biết sự biến thiên của các cá thể trong quần thể. Giả sử ta lấy mẫu k lần, và ta có k số trung bình. Để mô tả sự biến thiên của các số trung bình mẫu lấy từ tổng thể người ta sử dụng đại lượng sai số chuẩn (Standard Error –SE) được tính bằng cách lấy độ lệch chuẩn chia cho căn bậc hai của kích thước mẫu:

Tóm lại: Độ lệch chuẩn mô tả biến thiên của các cá thể trong quần thể còn sai số chuẩn mô tả sự biến thiên của các số trung bình mẫu lấy từ tổng thể. Một cách dễ hiểu nếu ta lấy mẫu k lần từ tổng thể và ta có k số trung bình mẫu thì độ lệch chuẩn của k số trung bình mẫu gọi là sai số chuẩn (chú ý k thường rất lớn, hàng triệu hay hàng tỷ lần vì trong thực tế ta không biết được số trung bình của tổng thể).
Tương quan (Correlation)
Trong lý thuyết xác suất và thống kê, hệ số tương quan (Coefficient Correlation) cho biết độ mạnh của mối quan hệ tuyến tính giữa hai biến số ngẫu nhiên. Từ tương quan (Correlation) được thành lập từ Co- (có nghĩa "together") và Relation (quan hệ).
Hệ số tương quan giữa 2 biến có thể dương (positive) hoặc âm (negative). Hệ số tương quan dương cho biết rằng giá trị 2 biến tăng cùng nhau còn hệ số tương quan âm thì nếu một biến tăng thì biến kia giảm.
Độ mạnh và hướng tương quan của 2 biến được mô tả như sau:
Hệ số tương quan có thể nhận giá trị từ -1 đến 1:
Ví dụ: Có dữ liệu (bivariate) về nhiệt độ (Temperature) và doanh thu bán kem (Ice Cream Sales) như sau:
Đồ thị Scatter Plot của dữ liệu trên :
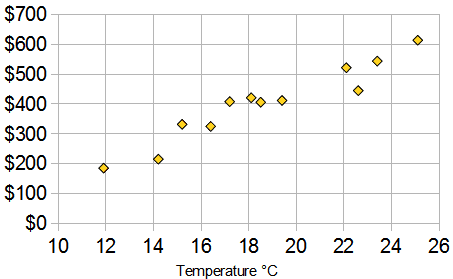
Từ Scatter Plot, ta có thể thấy rằng nhiệt độ càng cao thì doanh thu bán kem càng cao. Trong dữ liệu trên, hệ số tương quan là 0.9575 (sẽ trình bày cách tính ở phần sau) và mối quan hệ giữa nhiệt độ và doanh số bán kem là rất mạnh. Hệ số tương quan dương nói rằng nhiệt độ tăng thì doanh số bán kem cũng tăng.
Tương quan không có tính nhân quả (Causation).
Cách tính hệ số tương quan (Coefficient Correlation)
Trong ví dụ trên, hệ số tương quan là 0.9575. Bây giờ sẽ trình bày cách tính hệ số này theo công thức Pearson (Pearson's Correlation).
Gọi x và y là hai biến (Trong ví dụ trên thì x là Temperature và y là Ice Cream Sales)
· Bước 1: Tính trung bình của x và y
· Bước 2: Tính độ lệch của mỗi giá trị của x với trung bình của x (lấy các giá trị của x trừ đi trung bình của x) và gọi là "a", làm tương tự như vậy với y và gọi là "b"
· Bước 3: Tính: a × b, a2 và b2 cho mỗi giá trị
· Bước 4: Tính tổng a × b, tổng a2 vả tổng b2
· Bước 5: Chia tổng của a × b cho căn bậc 2 của [(sum a2) × (sum b2)]
Công thức chung để tính hệ số tương quan giữa 2 đại lượng ngẫu nhiên x và y là
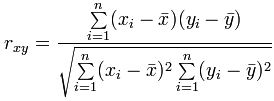
Dưới đây minh họa việc tính hệ số tương quan của ví dụ trên
Các tham số đo lường xu hướng tập trung và biến thiên của dữ liệu có thể được tính dễ dàng bởi các hàm trong MS Excel. Sau đây giới thiệu một số hàm liên quan và ví dụ minh họa cách tính các tham số trên trong MS Excel
Đo lường xu hướng trung (Central tendency)
AVERAGE: Tính trung bình số học (mean)
MEDIAN: Tính trung vị
MODE: Tính số mode
Đo lường độ biến thiên (Variation)
MAX – MIN : Tính Range
PERCENTILE (array, k) : Tìm phân vị thứ k của các giá trị trong một mảng dữ liệu
QUARTILE (array, 3) – QUARTILE (array, 1) : Tính Inter Quartile Range (IQR)
VAR : Tính phương sai của mẫu
VARPA: Tính phương sai tổng thể (Chú ý, công thức tính phương sai tổng thể giống như phương sai mẫu nhưng thay vì chia cho n-1 như phương sai mẫu thì chia cho n. trong đó n là kích thước mẫu)
STDEV : Tính độ lệch chuẩn của mẫu
STDEVPA Tính độ lệch chuẩn của tổng thể
Một số hàm liên quan khác
CORREL(): Tính hệ số tương quan
SUM : Tính tổng các số
SQRT: Căn bậc hai
CEILING : Ceiling function. CEILING(k) cho số nguyên nhỏ nhất lơn hơn k. Ví dụ : CEILING(3.5,1)=4
FLOOR : Floor function. FLOOR(k) cho số nguyên lớn nhất nhỏ hơn k. Ví dụ: FLOOR(3.5)=3)
Sau đây là ví dụ tính các tham số trên trong Excel với mẫu gồm 10 quan sát.
All comments please send to chuc1803@gmail.com. Thank you and Welcome!