Khai phá dữ liệu (Data Mining)
Nguyễn Văn Chức – chuc1803@gmail.com
“We are drowning in data but starving for knowledge”
Bài viết ngắn này trình bày sơ lược về lĩnh vực Khai phá dữ liệu nhằm giúp người đọc có cái nhìn ban đầu về lĩnh vực còn khá mới mẻ ở Việt Nam nhưng rất thú vị này.
1. Data Mining
Khái niệm về khai phá dữ liệu (Data Mining) hay phát hiện tri thức (Knowledge Discovery) có rất nhiều cách diễn đạt khác nhau nhưng về bản chất đó là quá trình tự động trích xuất thông tin có giá trị (thông tin dự đoán – Predictive Information) ẩn chứa trong khối lượng dữ liệu khổng lồ trong thực tế.
Data mining nhấn mạnh 2 khía cạnh chính đó là khả năng trích xuất thông tin có ích Tự động (Automated) và thông tin mang tính dự đoán (Predictive).
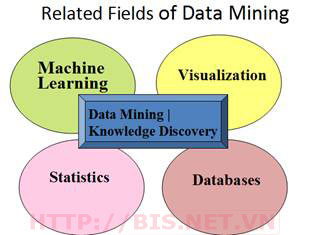
Data Mining liên quan chặt chẽ đến các lĩnh vực sau:
Statistics (Thống kê): Kiểm định model và đánh giá tri thức phát hiện được
Machine Learning (Máy học): Nghiên cứu xây dựng các giải thuật trên nền tảng của trí tuệ nhân tạo giúp cho máy tính có thể suy luận (dự đoán) kết quả tương lai thông qua quá trình huấn luyện (học) từ dữ liệu lịch sử.
Databases (Cơ sở dữ liệu): Công nghệ quản trị dữ liệu nhất là kho dữ liệu
Visualization (Trực quan hóa): Giúp dữ liệu dễ hiểu, dễ sử dụng như chart, map
2.Nhiệm vụ của Data Mining
Nhiệm vụ của data mining có thể phân thành 2 loại chính đó là dự đoán (Predictive) và mô tả (Descriptive).
Predictive:
· Classification : Phân lớp
Regression : Hồi qui
· Deviation Detection: Phát hiện độ lệch
Descriptive:
· Clustering: Phân cụm
· Association Rule Discovery: Phát hiện luật kết hợp
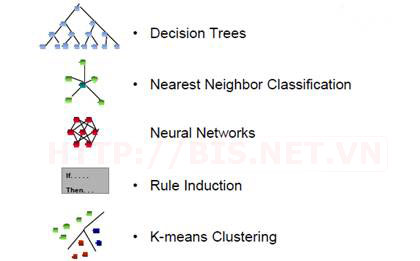
Dưới đây là một số thuật toán phổ biến được dùng trong Data Mining
Decision tree: Cây quyết định (Classification Task)
Nearest Neighbor: Láng giềng gần nhất (Classification Task)
Neural Network: Mạng Neural (Classification and Clustering Task)
Rule Induction: Luật qui nạp (Classification Task)
K-Means: Thuật toán K-Means ( Clustering Task)
Trong các bài sau, tôi sẽ lần lượt giới thiệu các thuật toán cụ thể để giải quyết các nhiệm vụ của Data Mining
3.Mô hình dự đoán (Predictive Model):
Là hộp đen (black box) thực hiện việc dự đoán tương lai dựa vào thông tin trong quá khứ và hiện tại.

Để có một mô hình dự đoán ta phải trải qua 2 giai đoạn (phase). Thứ nhất là xây dựng mô hình (Training phase)

và thứ hai là kiểm định mô hình (Testing phase)

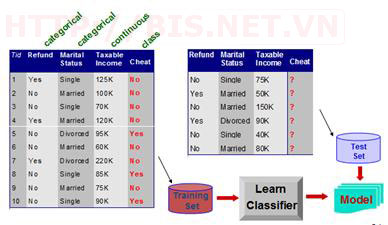
Ví dụ sau đây mô tả qui trình xây dựng mô hình phân lớp (Classifier)
Đánh giá mô hình dự đoán (Evaluate a Predictive Model)
Để đánh giá mô hình dự đoán hoạt động tốt thế nào người ta dựa vào các tham số sau: Recall, Accuracy, Precision, F-Measure,.. các công thứ tính như sau:

Để hiểu thêm về các tham số này, các bạn nên đọc thêm về các loại sai lầm trong thống kê (type 1 Error, Type 2 Error ) tại http://en.wikipedia.org/wiki/Type_I_and_type_II_errors
và Recall and Precision tại http://en.wikipedia.org/wiki/Precision_and_recall
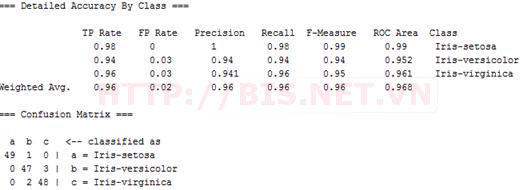
Các tham số này trong các phần mềm Data Mining hiện nay đã tính sẵn, ví dụ dưới đây là kết quả tính toán của mô hình phân lớp từ dữ liệu hoa Iris trong weka
(P.S. Next topic: Using Weka to Build Predictive Model for Classification Task
Comments please send to chucnv@ud.edu.vn)